6 purrr
6.1 INTRODUCCIÓN
- map: función que itera por un conjunto de elementos y cuyo output es una lista donde cada elemento de la lista corresponde al resultado de la operación para cada elemento iterado.
- walk: función que itera por un conjunto de elementos que no genera un output concreto, es una función procedimental (generar prints o gráficos, etc).
Si hicieramos un paralelo con lo que pasa en R-base u otros lenguajes, sería algo así:
# En R base:
for(elem in c(1, 2, 3, 4, 5)){
print(elem)
}# En python:
for elem in [1, 2, 3, 4, 5]:
print(elem)# En purrr:
c(1, 2, 3, 4, 5) %>%
map(function(elem){
print(elem)
})6.2 ITERACIÓN
A continuación se presenta un conjunto de lógicas de iteración que obedecen a la regla:
“si se itera por __ –> cada elemento de iteración es ___”
- df (excepto pmap/pwalk) –> cada columna del df.
- df (pmap/pwalk) –> cada fila del df.
- vector –> cada elemento del vector.
- lista –> cada elemento de la lista.
6.3 TIPOS DE OUTPUT
Dependiendo del tipo de output que se quiere en la lista final se puede agregar un “apellido” a la función segun la siguiente lógica:
- _lgl → output valor lógico (TRUE/FALSE).
- _int → output valor numérico entero.
- _dbl → output valor numérico que permite decimales.
- _chr → output character.
- _vec → output vector simplificado.
- _df → output dataframe
- _dfr → output dataframe unido por fila (ya no retorna lista, sino un dataframe único).
- _dfc → output dataframe unido por columna (ya no retorna lista, sino un dataframe único).
Los elementos _df, _dfr, _dfc ya no se recomiendan usar, en lugar de ellos se recomienda utilizar map y luego usar list_rbind() o list_cbind() para realizar la union de las bases.
6.4 ITERACIONES
map() | walk()
iterar por un elemento con una función de 1 parámetro, el valor.
iterador %>%
map(function(.x){
# .x: valor del elemento de iteración actual
# --- operación ---
})vector <- c(1, 5, 4, 3, 10)
resultado <-
vector %>%
map(function(.x){
.x * 10
})
map2() | walk2()
iterar por 2 elementos con una función de 1 parámetro para cada elemento.
map2(
iterador1,
iterador2,
function(param1, param2){
# param1: valor del elemento de iterador 1 para la iteración actual.
# param2: valor del elemento de iterador 2 para la iteración actual.
# --- operación ---
}
)lista1 <- list(1, 5, 10, 4, 2)
lista2 <- list(6, 5, 11, 9, 5)
resultado <-
map2(
lista1,
lista2,
function(param1, param2){
param1 + param2
}
)
imap() | iwalk()
iterar por un elemento con una función de 2 parámetros, el valor y el nombre del elemento.
iterador %>%
imap(function(.x, .y){
# .x: valor del elemento de iteración actual
# .y: nombre del elemento de iteración actual
# --- operación ---
})lista <- list(a = 1, b = 2, c = 3, d = 4)
resultado <-
lista %>%
imap(function(.x, .y){
paste0(.x, "_", .y)
})
pmap() | pwalk()
Existen dos casos notorios e independientes para esta familia.
- iterar por listas
- Se debe iterar por listas que tengan el mismo tamaño y para ingresarlas en pmap deben estar en si mismas contenidas en una lista.
list(
lista1 = list(),
lista2 = list(),
lista3 = list(),
...,
listan = list()
) %>%
pmap(function(i.lista1, i.lista2, i.lista3, ..., i.listan){
# i.lista1 corresponde al valor del elemento de la iteración actual para lista1
# i.lista2 corresponde al valor del elemento de la iteración actual para lista2
# i.lista3 corresponde al valor del elemento de la iteración actual para lista3
# i.listan corresponde al valor del elemento de la iteración actual para listan
# --- operación ---
})lista1 <- list(1, 2, 3, 4, 5)
lista2 <- list(2, 3, 4, 5, 6)
lista3 <- list(3, 4, 5, 6, 7)
resultado <-
list(
lista1,
lista2,
lista3
) %>%
pmap(function(i.lista1, i.lista2, i.lista3){
paste0(i.lista1, i.lista2, i.lista3)
})
- iterar por dataframes
- Al iterar por un df se fuerza a que todas las columnas de esa base de datos estén integradas en la iteración (o dará error), para no incluir algunas columnas en caso de un iterador muy largo terminar la función con “…”
- es obligatorio que los nombres de los parámetros en la función coincidan con los nombres de la columnas en el df.
df %>%
map(function(col1, col2, col3, ..., coln){
# col1 corresponde al valor de la columna col1 para la fila iterada.
# col2 corresponde al valor de la columna col2 para la fila iterada.
# col3 corresponde al valor de la columna col3 para la fila iterada.
# coln corresponde al valor de la columna col4 para la fila iterada.
# --- operación ---
})# crear df:
df <-
tibble(
col1 = c(1, 2, 3, 4, 5),
col2 = c(2, 3, 4, 5, 6),
col3 = c(3, 4, 5, 6, 7)
)
# mostrar df:
df %>%
gt()| col1 | col2 | col3 |
|---|---|---|
| 1 | 2 | 3 |
| 2 | 3 | 4 |
| 3 | 4 | 5 |
| 4 | 5 | 6 |
| 5 | 6 | 7 |
# uso de pmap:
resultado <-
df %>%
pmap(function(col1, col2, col3){
paste0(col1, col2, col3)
})
6.5 MANIPULACIONES DE LISTAS/VECTORES
list_flatten()
Aplana listas anidadas en 1 nivel desde menor a mayor anidación.
lista %>%
list_flatten()Si tenemos la lista:

Con 1 aplanamiento:
resultado <-
lista %>%
list_flatten()
Si tenemos la lista:
Con 2 aplanamientos:
resultado <-
lista %>%
list_flatten() %>%
list_flatten()
list_assign()
Modifica o crea un elemento de una lista por nombre o posición.
Cuando los parámetros tienen nombre se hace el match por nombre, si no llevan nombre se hace el match por posición.
lista %>%
list_assign(
"nombre1" = valor1,
"nombre2" = valor2,
"nombre3" = valor3,
"nombren" = valorn
)
lista %>%
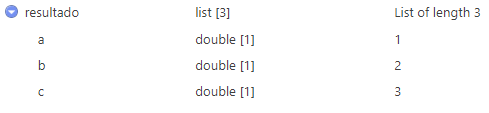
list_assign(valor1, valor2, valor3, ..., valorn)resultado <-
list() %>% # se parte desde una lista vacía
list_assign(
"a" = 1,
"b" = 2,
"c" = 3
)
resultado <-
list() %>% # se parte desde una lista vacía
list_assign(1, 2, 3)
list_transpose()
lista %>%
list_transpose()lista <-
list(
a1 = list(a = 1, b = 2),
b1 = list(a = 3, b = 4),
c1 = list(a = 5, b = 6)
)
resultado <-
lista %>%
list_transpose()
list_simplify()
Solo para listas con 1 nivel de anidación y con elementos del mismo tipo, crea un vector con los elementos.
lista %>%
list_simplify()lista <-
list(1, 2, 3, 4, 5)
resultado <-
lista %>%
list_simplify()
list_cbind()
Une dataframes contenidos en una lista en un único dataframe por columna.
list(
df1,
df2,
df3
) %>%
list_cbind()df1 <-
tibble(
a = c(1, 2, 3),
b = c(2, 3, 4)
)
df2 <-
tibble(
c = c(3, 4, 5),
d = c(4, 5, 6)
)
df3 <-
tibble(
e = c(5, 6, 7),
f = c(6, 7, 8)
)| a | b |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| c | d |
|---|---|
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| e | f |
|---|---|
| 5 | 6 |
| 6 | 7 |
| 7 | 8 |
lista <-
list(df1, df2, df3)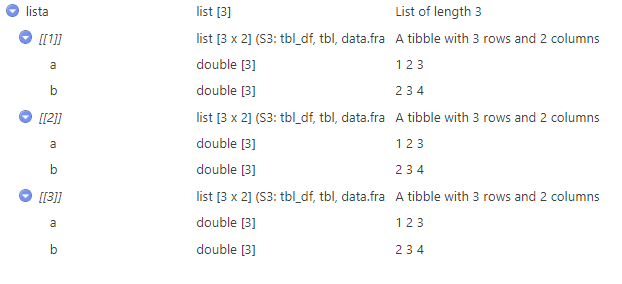
resultado <-
lista %>%
list_cbind()| a | b | c | d | e | f |
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 |
| 2 | 3 | 4 | 5 | 6 | 7 |
| 3 | 4 | 5 | 6 | 7 | 8 |
list_rbind()
Une dataframes contenidos en una lista en un único dataframe por fila.
df1 <-
tibble(
a = c(1, 2, 3),
b = c(2, 3, 4)
)
df2 <-
tibble(
a = c(3, 4, 5),
b = c(4, 5, 6)
)
df3 <-
tibble(
a = c(5, 6, 7),
b = c(6, 7, 8)
)| a | b |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| a | b |
|---|---|
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| a | b |
|---|---|
| 5 | 6 |
| 6 | 7 |
| 7 | 8 |
lista <-
list(df1, df2, df3)
resultado <-
lista %>%
list_rbind()| a | b |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| 5 | 6 |
| 6 | 7 |
| 7 | 8 |
pluck()
Extrae un elemento de una lista o vector por nombre o indice, devuelve “NULL” si el elemento no existe. Siempre extrae 1 elemento.
lista %>%
pluck(nombre/posicion)
resultado <-
lista %>%
pluck("a")
equivalente a lista[[“a”]]

resultado <-
lista %>%
pluck("c", "d")
equivalente a lista[[“c”]][[“d”]]
lista <-
list(
a = c(1, 2, 3),
b = c(5, 6, 7),
c = c(8, 9, 10)
)
resultado <-
lista %>%
pluck("d")
chuck()
Extrae un elemento de una lista o vector por nombre o indice, arroja error si el elemento no existe.
lista %>%
chuck(nombre/indice)
resultado <-
lista %>%
chuck("a")
equivalente a lista[[“a”]]

resultado <-
lista %>%
chuck("c", "d")
equivalente a lista[[“c”]][[“d”]]
lista <-
list(
a = c(1, 2, 3),
b = c(5, 6, 7),
c = c(8, 9, 10)
)
resultado <-
lista %>%
chuck("d")Error in chuck(., “d”) : Can’t find name d in vector.
pluck_depth()
Cuenta los niveles de anidación mayor contenido en la lista
lista %>%
pluck_depth()lista <-
list(
"1" =
list(
"2" = list(3)
),
"2" =
list(
"2" = list(5)
),
"3" =
list(
"2" = list(7)
)
)
resultado <-
lista %>%
pluck_depth()
keep()
Utiliza un criterio dentro de una función basado en el valor de cada elemento de una lista o vector para mantener elementos.
lista %>%
keep(function(.x){
# .x: valor de cada elemento de la lista.
})lista <-
list(
a = 1,
b = 2,
c = 3,
d = 4,
e = 5
)
resultado <-
lista %>%
keep(function(.x){
.x >= 3
})
keep_at()
Utiliza un criterio dentro de una función basado en el nombre de cada elemento de una lista o vector para mantener elementos.
lista %>%
keep_at(function(.x){
# .x: nombre de cada elemento de la lista.
})lista <-
list(
a = 1,
b = 2,
c = 3,
d = 4,
e = 5
)
resultado <-
lista %>%
keep_at(function(.x){
.x %in% c("d", "e")
})
discard()
Utiliza un criterio dentro de una función basado en el valor de cada elemento de una lista o vector para filtrar elementos.
lista %>%
discard(function(.x){
# .x: valor de cada elemento de la lista.
})lista <-
list(
a = 1,
b = 2,
c = 3,
d = 4,
e = 5
)
resultado <-
lista %>%
discard(function(.x){
.x >= 3
})
discard_at()
Utiliza un criterio dentro de una función basado en el nombre de cada elemento de una lista o vector para filtrar elementos.
lista %>%
discard_at(function(.x){
# .x: nombre de cada elemento de la lista.
})lista <-
list(
a = 1,
b = 2,
c = 3,
d = 4,
e = 5
)
resultado <-
lista %>%
discard_at(function(.x){
.x %in% c("d", "e")
})